MySQL复习笔记-I
MySQL中一些重点知识的复习笔记,内容摘自书和一些学习视频,并会持续不断的完善。
测试数据来源:MySQL官方employees数据库。
MySQL复习笔记-I
MySQL复习笔记-II
MySQL复习笔记-III
MySQL复习笔记-IV
基础知识
DB、DBMS、DBA
DDL、DCL、DML
常见MySQL命令行命令。
基础查询、条件查询(where)、常见函数(分组函数)、分组查询(group by/having)、排序查询(order by)、连接查询、子查询、分页查询(limit)、联合查询(union)。
基础查询
1 | /* |
条件查询
1 | /* |
常见函数
1 | /* |
排序查询
1 | /* |
分组查询
1 | /* |
连接查询
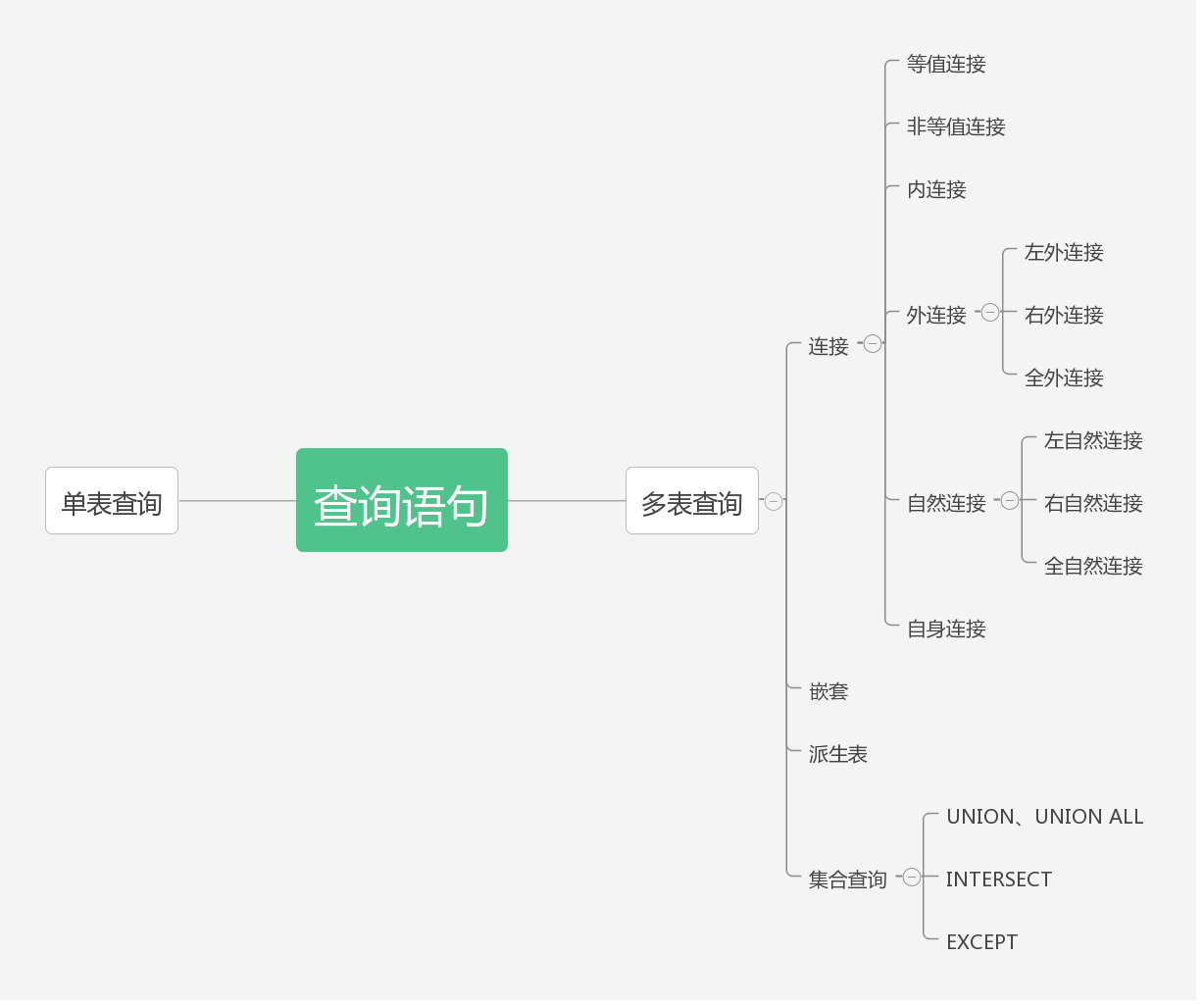
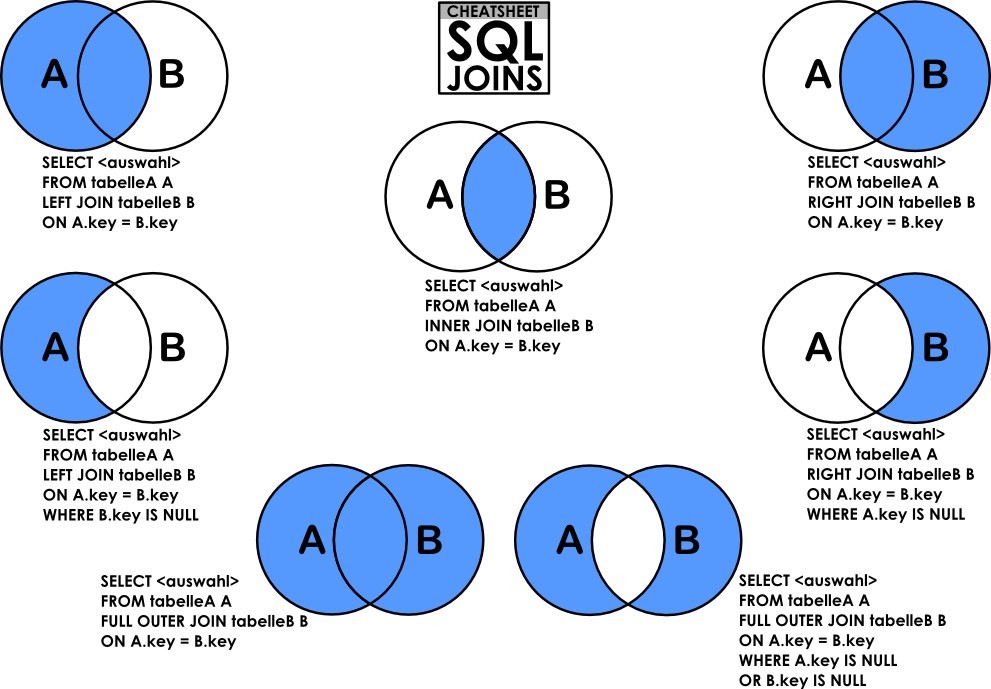
SQL92语法
1 | /* |
SQL99语法
1 | /* |
子查询
1 | /* |
分页查询
1 | /* |
联合查询
1 | /* |